深入理解Python的set和dict(不涉及源码分析,想看源码分析的可以关闭了,源码分析后期会出)
集合(set)和字典(dict)的内部原理
Python 的 dict 和 set 构建在哈希表之上。这篇文章解释了哈希表的使用如何造成这些容器类型的优点和局限性。
以下是本文回答的一些问题:
Python dict 和 set 的效率如何?
为什么集合元素是无序的?
为什么我们不能使用任何 Python 对象作为 dict 键或 set 元素?
为什么字典键的顺序取决于插入顺序
本文内容:
性能试验
哈希和相等
哈希表
哈希算法
集合工作原理造成的实际影响
Dict中哈希表的使用
Key共享字典
紧凑的 dict 如何节省空间并保持排序
dict 工作原理造成的实际影响
注意:您无需了解所有这些细节即可充分利用字典和集合。但这两个结构的实现想法很美好——这就是我描述它们的原因。如需实用建议,您可以跳至“集合的工作原理造成的实际影响”和“字典的工作原理造成的实际影响”章节。
为了激发对哈希表的研究,我们首先通过涉及数百万个项目的简单测试来展示 dict 和 set 的惊人性能。
性能试验
根据经验,所有 Pythonista 都知道字典和集合速度很快。我们将通过对照实验来证实这一点。
为了了解dict、set或list的大小如何影响使用 in 运算符的搜索性能,我生成了一个包含 1000 万个不同双精度浮点数的数组,即“干草堆(haystack)”。然后我生成了一组针:即1,000 个浮点数,其中 500 个是从干草堆中挑选出来的,500 个已验证不在其中。
对于 dict 基准测试,我使用 dict.fromkeys() 创建一个名为 haystack 的包含 1,000 个浮点数的字典。这是 dict 测试的设置。我使用 timeit 模块计时的实际代码是示例 1(如 [ex_set_loop_ex])。
例 1. 在干草堆中寻找针,并对找到的针进行计数
found = 0
for n in needles:
if
n in haystack:
found += 1
我重复了基准测试五次,每次将
haystack 的大小增加十倍,从 1,000 项增加到 10,000,000 项。 dict性能测试结果如图1所示。(haystack的大小依次是1000,10000,100000,1000000,10000000)

图1,表3-6
具体而言,要检查包含 有1,000 个项目的字典中是否存在 1,000 个浮点键,我的笔记本电脑上的处理时间为 99μs,而在包含 有10,000,000 个项目的字典中进行相同的搜索需要 512μs。换句话说,在包含 1000 万个项目的大海捞针中每次搜索的平均时间为 0.512 微秒,是的,这大约是查找一项耗时半微秒(查找1000项就差不多500μs)。当搜索空间扩大 10,000 倍时,搜索时间增加了 5 倍多一点。非常帅气!
为了与其他集合类型进行比较,我使用尺寸不断增加的相同干草堆重复了基准测试,但将干草堆存储为set或list。对于set测试,除了对示例 1 中的 for 循环进行计时之外,我还对示例 2 中的一行代码进行计时,这会产生相同的结果:计算同样位于 haystack 中的 needles 中的元素数量(如果两者都是set) 。
示例 2. 使用集合交集来计算 haystack 中出现的needles数
found = len(needles & haystack)
图 2 并排显示了测试。最佳时间位于“set& time”列中,该列使用示例 2 中的代码显示 set & 运算符的结果。正如预期的那样,最差时间位于“list time”列中,因为list的in运算符不支持使用哈希表进行搜索,因此如果要查找的needle不存在于haystack上时,则必须进行完整扫描,从而导致时间随着haystack的大小而线性增长.

图2 表3-7
如果您的程序执行任何类型的 I/O,那么无论 dict 或set的大小如何(只要能放入 RAM 中),dict 或set中键的查找时间都可以忽略不计。请参阅用于生成 [set_dict_search_time_tbl] 的代码以及 [support_scripts], [support_container_perftest] 中的相关讨论。
现在我们有了关于字典和集合速度的具体证据,让我们探索一下如何在哈希表的帮助下实现这么快的键查找速度。
在研究哈希表之前,我们需要更多地了解哈希码,以及它们与相等性的关系。
哈希和相等
内置函数 hash() 可直接用于内置类型,而对于用户自定义类型,则hash函数会退回调用 __hash__。如果两个对象的比较值相等,它们的哈希码也必须相等,否则哈希表算法就不起作用。例如,因为 1 == 1.0 为 True,所以 hash(1) == hash(1.0) 也必须为 True,尽管 int 和 float 的内部表示非常不同[1]。
此外,为了有效地用作哈希表索引,哈希码应尽可能分散在索引空间中。这意味着,在理想情况下,相似但不相等的对象的哈希码应该相差很大。例 3 是比较哈希码的位模式的脚本。请注意 1 和 1.0 的哈希码是相同的,但 1.0001、1.0002 和 1.0003 的哈希值却大不相同。
例 3. 在 Python 的 32 位构建上比较 1、1.0001、1.0002 和 1.0003 的哈希码位模式(上面和下面哈希中不同的位用 ! 标出,右栏显示不同位的数量)。
32-bit Python build1 00000000000000000000000000000001 != 01.0 00000000000000000000000000000001------------------------------------------------1.0 00000000000000000000000000000001 ! !!! ! !! ! ! ! ! !! !!! != 161.0001 00101110101101010000101011011101------------------------------------------------1.0001 00101110101101010000101011011101 !!! !!!! !!!!! !!!!! !! ! != 201.0002 01011101011010100001010110111001------------------------------------------------1.0002 01011101011010100001010110111001 ! ! ! !!! ! ! !! ! ! ! !!!! != 171.0003 00001100000111110010000010010110------------------------------------------------
注意:
从 Python 3.3 开始,计算 str、bytes 和 datetime 对象的哈希码时会包含随机盐(salt)值,如问题 13703 — 哈希冲突安全问题中所述。 salt 值在 Python 进程中是恒定的,但在解释器之间会有所不同。在 PEP-456 中,Python 3.4 采用了 SipHash 加密函数来计算 str 和 bytes 对象的哈希码。随机盐和 SipHash 是防止 DoS 攻击的安全措施。详细信息请参阅 __hash__ 特殊方法的文档中的注释。
哈希冲突
如前所述,在 64 位 CPython 上,哈希码是一个 64 位数字,有 2的64次方 个可能的值,超过 10的19次方 个。但大多数 Python 类型可以表示更多不同的值。例如,由随机选取的 10 个 ASCII 可打印字符组成的字符串有 100的10次方 个可能值,超过 2的66次方 个。因此,对象的哈希码所包含的信息通常少于实际对象数量。这意味着不同的对象可能具有相同的哈希码(说白了就是哈希码不够)。
提示:当正确实现时,哈希算法可以保证不同的哈希码始终意味着不同的对象,但反之则不然:不同的对象并不总是具有不同的哈希码。当不同的对象具有相同的哈希码时,这就是哈希冲突。
通过对哈希码和对象相等性的基本了解,我们准备好深入研究哈希表的工作原理以及哈希冲突的处理方式。
哈希表
哈希表是一项奇妙的发明。让我们看看在向set添加元素时如何使用哈希表。
假设我们有一组缩写的工作日,创建如下:
>>> workdays = {'Mon', 'Tue', 'Wed', 'Thu', 'Fri'}>>> workdays{'Tue', 'Mon', 'Wed', 'Fri', 'Thu'}
Python set的核心数据结构是一个至少有8行的哈希表。传统上,哈希表中的行称为桶(buckets)[2]。

图 3的set {'Mon', 'Tue', 'Wed', 'Thu', 'Fri'} 哈希表。每个桶有两个字段:哈希码和指向元素值的指针。空桶的哈希码字段为 -1。并且看起来是随机的。
在为 64 位 CPU 构建的 CPython 中,集合中的每个存储桶都有两个字段:一个 64 位哈希码和一个指向元素值的 64 位指针(元素值是存储在内存中其他位置的 Python 对象)。由于存储桶具有固定大小,因此可以通过从哈希表开头开始的偏移量来访问各个存储桶。换句话说,图3中的索引0到7没有被存储,它们只是偏移量。
哈希算法
我们将首先关注set的内部结构,然后将这些概念迁移到 dict 中。
注意:这是 Python 如何使用哈希表来实现set的简化视图。有关所有详细信息,请参阅 Include/setobject.h 和 Objects/setobject.c 中 CPython 的 set 和 freezeset 的注释源代码。
让我们来看看 Python 是如何一步步构建一个像 {'Mon', 'Tue', 'Wed', 'Thu', 'Fri'} 这样的集合的。图 4 中的流程图展示了该算法,接下来将对其进行描述。

图 4. 将元素添加到集合的哈希表的算法流程图。
步骤0: 初始化哈希表
如前所述,set的哈希表以 8 个空桶开始。添加元素时,Python 确保至少 ⅓ 的存储桶是空的——当需要更多空间时,将哈希表的大小加倍。每个桶的哈希码字段初始化为-1,表示“无哈希码”[3]。
步骤 1:计算元素的哈希码
对于给定的 {'Mon', 'Tue', 'Wed', 'Thu', 'Fri'},Python 获取第一个元素 'Mon' 的哈希码。例如,下面是“Mon”的真实哈希码 - 由于 Python 使用随机盐来计算字符串的哈希码,您的计算机可能会计算出不同的结果:
>>> hash('Mon')4199492796428269555
步骤 2:根据哈希码计算得出的索引来探测哈希表
Python 采用哈希码与表大小的模来查找哈希表索引。这里表的大小是8,模数是3:
>>> 4199492796428269555 % 83
探测包括根据哈希计算索引,然后查看哈希表中相应的存储桶。在本例中,Python 查看偏移量 3 处的存储桶,此时在哈希码字段中找到 -1,表示这是空存储桶。
步骤3:将元素放入空桶中
Python 将新元素”Mon”的哈希码 4199492796428269555 存储在偏移量 3 处的哈希码字段中,并在元素字段中存储指向字符串对象“Mon”的指针。图 5 显示了哈希表的当前状态。

图 5. 集合 {'Mon'} 的哈希表。
剩余元素的步骤
对于第二个元素“Tue”,重复上面的步骤 1、2、3。 “Tue”的哈希码是2414279730484651250,结果索引是 2。
>>> hash('Tue')2414279730484651250>>> hash('Tue') % 82
哈希值和指向元素“Tue”的指针被放置在桶 2 中,该桶之前也是空的。现在我们得到了图6

图 6.集合 {'Mon', 'Tue'} 的哈希表。请注意,哈希表中不保留元素排序。
发生哈希碰撞时的步骤:
将“Wed”添加到集合中时,Python 计算哈希值 -5145319347887138165 和索引 3。Python 探测存储桶 3 处并发现它已被占用。但存储在那里的哈希码 4199492796428269555 与”Wed”的哈希码是不同的。正如哈希和相等一节中所讨论的,如果两个对象具有不同的哈希码,那么它们的值也不同,所以这是索引冲突。然后 Python 探测下一个存储桶并发现它是空的。因此“Wed”最终位于索引 4 处的存储桶,如图 7 所示。

图 7.集合 {'Mon', 'Tue', 'Wed'} 的哈希表。碰撞后,“Wed”被置于索引 4 处。
添加下一个元素“Thu”很无聊:没有碰撞,它落在索引 7 处的自然桶中。
放置“Fri”更有趣。它的哈希值 7021641685991143771 意味着索引 3,这里由“Mon”占用。探测下一个存储桶 4 - Python 找到存储在那里的“Wed”的哈希值。哈希码也是不相同的,因此这是另一个索引冲突。 Python 探测下一个存储桶。它是空的,因此“Fri”最终位于索引 5 处。哈希表的最终状态如图 8 所示。
注意:碰撞后增加索引称为线性探测。这可能会导致被占用的桶成簇,从而降低哈希表的性能,因此 CPython 会计算线性探针的数量,并在达到一定阈值后,应用伪随机数生成器从哈希码其他位来获取不同的索引。这种优化在大型集合中尤其重要。

图 8.集合 {'Mon', 'Tue', 'Wed', 'Thu', 'Fri'} 的哈希表。现在已满 62.5%,接近 ⅔ 阈值。
当探测到的桶中有元素并且哈希码又相同时,Python还需要比较实际的对象值。这是因为,正如哈希冲突中所解释的,两个不同的对象可能具有相同的哈希码,尽管这对于字符串来说很少见,这要归功于 Siphash 算法的质量[4]。这解释了为什么可哈希对象必须同时实现 __hash__ 和 __eq__。
如果将一个新元素添加到我们的示例哈希表中,此时的哈希表将超过 ⅔ 满,因此增加了索引冲突的机会。为了防止这种情况发生,Python 将分配一个包含 16 个桶的新哈希表,并在那里重新插入所有元素。
所有这些看似工作量很大,但即使在一个集合中有数百万个元素的情况下,许多插入操作也不会发生碰撞,每次插入的平均碰撞次数在一到两次之间。在正常使用情况下,即使是最倒霉的元素,也能在解决少量碰撞后被放置。
现在,根据我们到目前为止所看到的内容,按照图 4 中的流程图,在不使用计算机的情况下回答下面的问题。
给定以下集合,当向其中添加整数 1 时会发生什么?
>>> s = {1.0, 2.0, 3.0}>>> s.add(1)
现在 s 中有多少个元素?1 是否替换了元素 1.0?得到答案后,请使用 Python 控制台验证。
在哈希表中搜索元素
考虑使用图 8 所示的workdays集合的哈希表,这个哈希表有“Sat”吗?’Sat’ in workdaysd的最简单的执行路径如下:
1:调用 hash('Sat') 获取哈希码。假设结果是 4910012646790914166
2:使用 hash_code % table_size 从哈希码计算出哈希表索引。在本例中,索引为 6。
3:探测哈希表的偏移 6:它是空的。这意味着“Sat”不在集合中,返回False。
现在考虑集合中存在元素的最简单的情况。比如“Thu” ins workdays:
1:调用 hash('Tue')。假设结果是 6166047609348267525。
2:计算索引:6166047609348267525 % 8 为 5。
3:探测哈希表的偏移 5:
比较哈希码,是相等的。
比较对象值,是相等的。返回True。
如果发生碰撞按照添加元素时描述的方式进行处理。事实上,图 4 中的流程图也适用于搜索,但终端节点(带圆角的矩形)除外。如果找到空桶,则该元素不存在,因此 Python 返回 False;否则,当查找元素的哈希码和值都与哈希表中的元素匹配时,返回 True。
集合工作原理的实际影响
set 和 freezeset 类型都是通过哈希表实现的,具有以下效果:
集合元素必须是可哈希对象。他们必须实现正确的 __hash__ 和 __eq__ 方法,如 [what_is_hashable] 中所述。
成员测试非常高效。一个集合可能有数百万个元素,但通过计算元素的哈希码并计算出一个索引偏移量,就能直接找到元素的数据桶,只需少量探测就能找到匹配的元素或空数据桶。
集合有很大的内存开销。容器最紧凑的内部数据结构是指针数组[5]。相比之下,哈希表为每个条目添加一个哈希码,以及至少 ⅓ 的空桶以最大限度地减少冲突。
元素排序取决于插入顺序,但不是以有用或可靠的方式。如果两个元素发生冲突,则每个元素存储的存储桶取决于首先添加的元素。
将元素添加到集合中可能会更改其他元素的顺序。这是因为,当哈希表被填满时,Python 可能需要重新创建哈希表以保持至少 ⅓ 的存储桶为空。发生这种情况时,元素将被重新插入,并且可能会发生不同的冲突。
Dict中哈希表的使用
愿你的哈希值独一无二、
你的键很少碰撞
你的字典
永远有序
— Brandon Rhodes
in The Dictionary Even Mightier
自 2012 年以来,dict 类型的实现进行了两次重大优化,以减少内存使用量。第一次是作为 PEP 412 - Key-Sharing Dictionary 提出的,并在 Python 3.3 中实现[7]。第二个被称为 "紧凑 dict`",在 Python 3.6 中实现。作为附带效果,紧凑的 "dict "空间优化保留了键的插入顺序。在接下来的章节中,我们将依次讨论紧凑型 dict 和新的key-sharing方案,以方便表述。
紧凑的 dict 如何节省内存空间并保持插入顺序
注意:这是 Python dict 实现的高级解释。不同之处在于 dict 哈希表的实际可用部分是 ⅓,而不是集合中的⅔。如果使用实际的 ⅓ 分数,就需要 16 个桶才能容纳我的 dict 示例中的 4 个元素,本节中的图就会变得太高,所以我在这些解释中假装可用分数是 ⅔。Objects/dictobject.c 中的一条注释解释说,介于 ⅓ 和 ⅔ 之间的任何分数 "在实践中似乎都很有效"。
考虑一个dict,其中包含从“Mon”到“Thu”的工作日的缩写名称,以及每天参加游泳课的学生人数:
>>> swimmers = {'Mon': 14, 'Tue': 12, 'Wed': 14, 'Thu': 11}
在紧凑字典优化之前,swimmers字典底层的哈希表将如图 9 所示。如您所见,在 64 位 Python 中,每个桶保存三个 64 位字段:分别是键的哈希码、指向键对象和指向值对象的指针。即每个桶 24 字节。

图 9. 具有 4 个键值对的字典的旧哈希表格式。每个桶都是一个结构体,其中包含键的哈希码、指向键的指针和指向值的指针。
前两个字段的作用与实现集合时的作用相同。要找到一个键,Python 会计算键的哈希码,从哈希码计算出一个索引,然后通过这个索引探测哈希表,找到一个具有匹配的哈希码和匹配的键对象的桶。第三个字段提供了 dict 的主要功能:将键映射到任意值。键必须是可哈希对象,哈希表算法确保它在 dict 中是唯一的。但值可以是任何对象,并不需要是可哈希的或唯一的。
Raymond Hettinger 观察到,如果哈希码以及指向键和值的指针保存在没有空行的entries数组中,并且实际的哈希表是一个稀疏数组,其中的存储桶保存指向entries数组的索引,则可以节省大量内存[8]。在他给 python-dev 的原始消息中,Hettinger 将其称为哈希表indices。indices中存储桶的宽度随着字典的增长而变化,从每个存储桶 8 位开始,足以索引最多 128 个条目,同时保留负值用于特殊目的,例如 -1 表示空,-2 表示删除。
例如,swimmers字典将被存储,如图 10 所示。

图 10. 具有 4 个键值对的字典的紧凑存储。哈希码以及指向键和值的指针按插入顺序存储在entries数组中,并且从哈希码计算出来的元素偏移量保存在indices稀疏数组中,其中索引值 -1 表示空桶。
假设 CPython 是 64 位版本,我们的 4 项swimmers字典在旧方案中将占用 192 字节内存:每个存储桶 24 字节,乘以 8 行。等效的紧凑字典总共使用 104 个字节:条目中的 96 个字节 (24 * 4),加上indices中的存储桶共有 8 个字节 - 配置为 8 个字节的数组。
下一节将介绍如何使用这两个数组。
将项添加到紧凑字典的算法。
步骤1:设置INDICES
indices表最初设置为有符号字节数组,有 8 个桶,每个桶都用 -1 初始化以表示“空桶”。这些存储桶中最多有 5 个用于保存entries数组中行号,其中 ⅓ 为 -1。另一个数组,即entries,将保存键/值数据,其三个字段与旧方案中相同,但按插入顺序排列。
步骤1:计算键的哈希码
为了将键值对 ('Mon', 14) 添加到 Swimmers 字典中,Python 首先调用 hash('Mon') 来计算该键的哈希码。
步骤2:通过indices探测entries
Python 计算 hash('Mon') % len(indices)。在我们的示例中,结果是3。Indices数组中的偏移量 3 处保存的是 -1:它是一个空桶。
步骤3:把KEY-VALUE插入entries数组中,并更新INDICES数组
entries数组为空,因此下一个可用偏移量为 0。Python 将 0 放置在indices中的偏移量 3 处,并存储键的哈希码、指向键对象“Mon”的指针以及指向 int 值 14 的指针在entries中的偏移量 0 处。图 11 显示了当 Swimmers 的值为 {'Mon': 14} 时数组的状态。

图 11. {'Mon': 14} 的紧凑存储:indices[3] 保存第一个项entries[0]的偏移量。
添加下一个的步骤如下:
将 ('Tue', 12) 添加到swimmers中:
1:计算键“Tue”的哈希码。
2:计算indices的偏移量,如 hash('Tue') % len(indices),计算结果是 2。indices[2] 的值为 -1。目前还没有发生碰撞。
3:将下一个可用项的偏移量 1 放入indices [2] 中,然后将项(键值对)存储在entries [1] 中。
现在的状态如图 12 所示。请注意,字典的项(键值对)按插入顺序保存键值对。

图 12.{'Mon': 14, 'Tue': 12} 的紧凑存储。
发生哈希冲突的处理如下:
1:计算键“Wed”的哈希码。
2:现在, hash('Wed') % len(indices) 为3。indices[3] 为 0,指向现有项。查看entries[0]中的哈希码,这是“Mon”的哈希码,它恰好与“Wed”的哈希码不同。这种不匹配表明发生了冲突。探测下一个索引:indices[4]。这是-1,所以可以使用。
3:使 indices[4] = 2,因为 2 是entries 的下一个可用偏移量。然后像往常一样填充 entries[2]。
添加 ('Wed', 14) 后,我们得到图 13
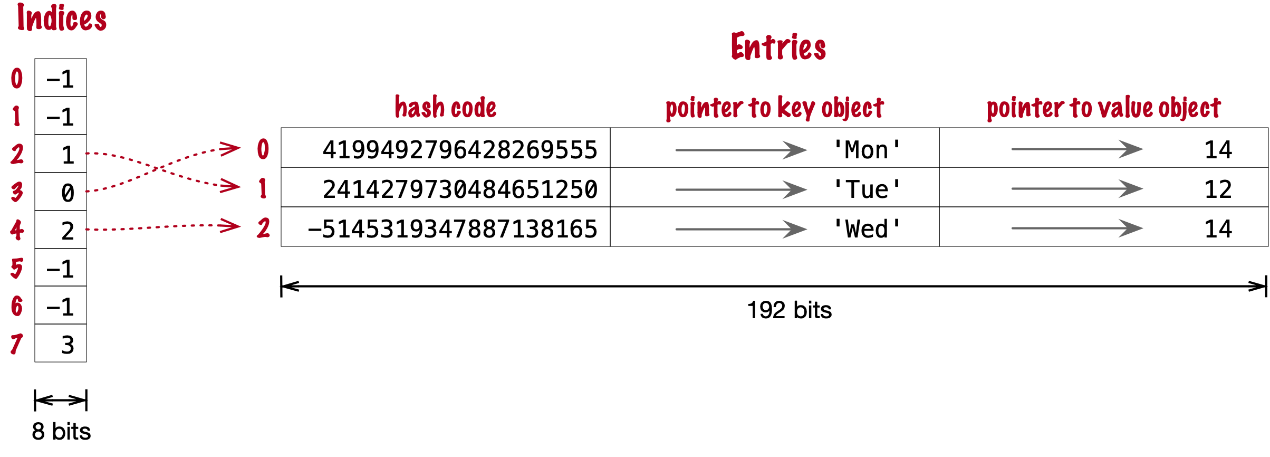
图 13.{'Mon': 14, 'Tue': 12, 'Wed': 14} 的紧凑存储。
紧凑字典如何增长
回想一下,indices数组中最初就是 8 个存储桶(每个桶是存储8bit的有符号数),所以容纳最多 5 个项的偏移量,因为要使 ⅓ 的存储桶为空。当第 6 个项(键值对)添加到字典中时,indices将重新分配到 16 个存储桶,此时就足以容纳 10 个项的偏移量。Indices数组的大小根据需要加倍,同时仍然保留有符号字节(桶仍然是8位的有符号数),直到将第 129 项(键值对)添加到字典中为止。此时,indices数组有 256 个 8 位桶。然而,一个有符号字节不足以保存 128 个项之后的偏移量,因此indices数组被重建以容纳 256 个 16 位存储桶来保存有符号整数 — 宽度足以表示entries表中 32,768 行的偏移量。下一次调整大小发生在第 171 次添加时,此时索引将超过 ⅔ 满。然后indices中的桶数量加倍到 512,但每个桶仍然是 16 位宽。总之,indices数组的增长是通过将存储桶的数量加倍来实现的,并且也(不太常见)通过将每个存储桶的宽度加倍来容纳entries中不断增长的行数。
我们对紧凑字典实现的总结到此结束。我省略了很多细节,但现在让我们看看字典的另一个节省空间的优化:key-sharing。
key-sharing字典
用户定义类的实例会将实例属性保存在 __dict__ [9] 中,这是一个普通的字典。实例的 __dict__ 将属性名映射为属性值。大多数情况下,所有实例的属性相同,但值不同。在这种情况下,每个实例的entries表中的 3 个字段有 2 个内容完全相同:属性名的哈希码和指向属性名的指针。只有指向属性值的指针是不同的。
(比如Person类,有firstname和lastname两个属性,假设从Person类实例化出A和B对象,实例A的__dict__设为{‘firstname’:’xiaoming’, ‘lastname’:’wang’},实例B的__dict__设为{‘firstname’:’tianliang’, ‘lastname’:’lee’},
A对象的__dict__的entries表如下:
|
Hash code |
Key |
Value |
|
2794085227598946724 |
“firstname” |
“xiaoming” |
|
-5818700193533911070 |
“lastname” |
“wang” |
B对象的__dict__的entries表如下:
|
Hash code |
Key |
Value |
|
2794085227598946724 |
“firstname” |
“tianliang” |
|
-5818700193533911070 |
“lastname” |
“lee” |
这仅仅是两个对象,一个运行起来的系统如果有100,或者10000个Person对象呢,如果Person有100个属性呢?
在 PEP 412 — Key-Sharing Dictionary 中,Mark Shannon 提出将用作实例 __dict__ 的字典的存储进行分割,使得每个属性的哈希码和指向属性的指针只存储一次,链接到类中(由类来保存),并且属性的值保存在为每个实例附加的并行数组中。
给定一个 Movie 类,其中所有实例都具有名为“title”、“release”、“directors”和“actors”的相同属性,图 14 显示了拆分字典中key-sharing的安排 — 也是使用新的紧凑布局实现的。

图 14.类和三个实例的 __dict__ 的拆分存储。
PEP 412 引入了合并表(combined-table)来讨论旧的布局和拆分表(split-table)来做优化。
使用字面语法或调用 dict() 创建字典时,combined-table布局仍是默认布局。当创建类的第一个实例时,会创建一个
split-table 字典来填充这个实例的 __dict__ 属性,然后,键表(见图 14)会缓存在类对象中。这利用了大多数面向对象 Python 代码在 __init__ 方法中分配所有实例属性的事实。第一个实例(及其后的所有实例)将只保存自己的值数组。如果一个实例获得了共享键表中没有的新属性,那么这个实例的 __dict__ 将被转换为combined-table形式。但是,如果该实例是其类中的唯一实例,则__dict__会转换回split-table,因为我们假定以后的实例将具有相同的属性集,并且键共享是可用的。
在 CPython 源代码中表示字典的 PyDictObject 结构对于combined-table和split-table字典是相同的。当字典从一种布局转换为另一种布局时,在其他内部数据结构的帮助下,PyDictObject
字段中会发生变化。
dict 工作原理造成的实际影响
1:键必须是可哈希的对象。他们必须实现正确的 __hash__ 和 __eq__ 方法,如 [what_is_hashable] 中所述。
2:键搜索几乎与集合中的元素搜索一样快。
3:项(键值对)按照插入顺序保留在entries表中 - 这是在 CPython 3.6 中实现的,并在 3.7 中成为官方语言功能。
4:为了节省内存,请避免在 __init__ 方法之外创建实例的属性。如果所有实例属性都是在 __init__ 中创建的,则实例的 __dict__ 将使用split-table布局形式,就共享类中存储的相同indices和键条目数组

评论
发表评论